
컴퓨터 비전에 관심을 가지게 되면서 딥러닝 분야를 공부해야겠다고 생각해서 coursera의 심층학습 특화과정(Deep Learning Specialization)을 수강하였다.
강좌 1) Neural Networks and Deep Learning - 신경망 및 딥 러닝
강좌 2) Improving Deep Neural Networks - 하이퍼파라미터 튜닝, 정규화, 그리고 최적화
강좌 3) Structuring Machine Learning Projects - 머신 러닝 프로젝트 구축하기
강좌 4) Convolutional Neural Networks - 합성곱 신경망 (CNN)
강좌 5) Sequence Models - 시퀀스 모델
Neural Network란?
우리는 인풋 x가 주어졌을 때 결과값 y를 찾고 싶어한다. 이 때 간단한 숫자 계산이라면 잘 알려진 함수를 사용할 수 있는데, 현실 세계의 데이터(이미지, 오디오 등)가 여러 차원으로 이루어진 인풋이라면 간단한 함수로 결과값을 얻어내는 것이 불가능하다. 이러한 복잡한 데이터에 적용되는 함수를 잘 찾아내기 위해 여러 층으로 뉴런을 쌓아 만든 것이 신경망(Neural Network)이다.
Neural Network를 통해 찾아내고자 하는 것은 파라미터 w (weight)와 b (bias)이다. y=wx+b의 식에서 w와 b를 알아낸다면, 어떠한 인풋 x가 들어오든 y값(결과값)을 계산해낼 수 있다. 신경망이 파라미터 w와 b를 찾아내는 과정을 '학습한다'고 하는데, 이 때 손실함수(loss function)가 사용된다. 현재의 w와 b를 이용해 계산한 결과값이 실제 정답과 얼마나 떨어져있는지(loss)를 계산해 그 loss가 0이 되도록 w와 b를 계속해서 수정해나간다. 따라서 신경망이 파라미터를 학습하기 위해서는 x 뿐 아니라 정답 label인 y를 알고 있어야 한다. 다만 y를 모르는 경우에도 y를 도출해서 학습할 수 있는데, 알고 있는 경우를 supervised learning, 모르는 경우를 unsupervised learning이라고 한다.
Gradient Descent의 속도를 높이는 방법들
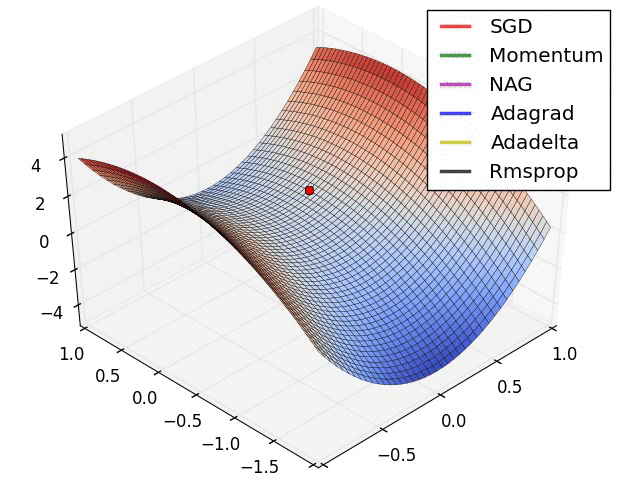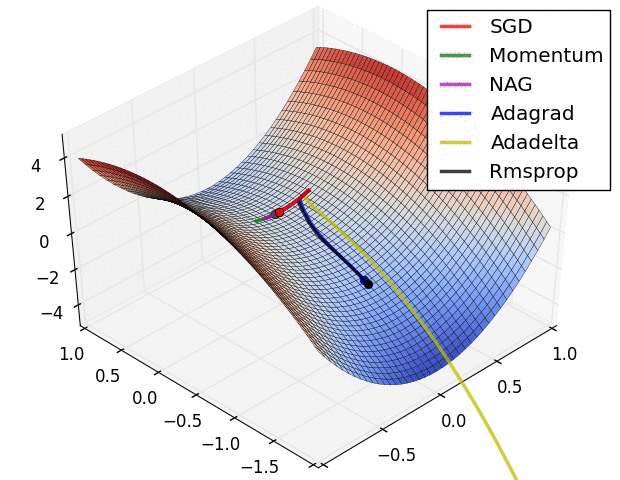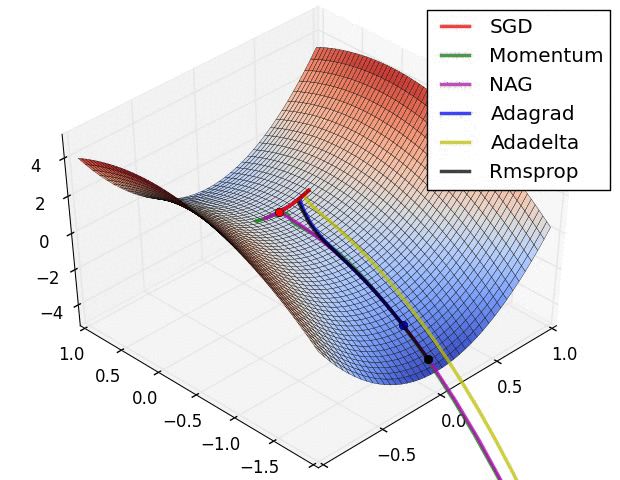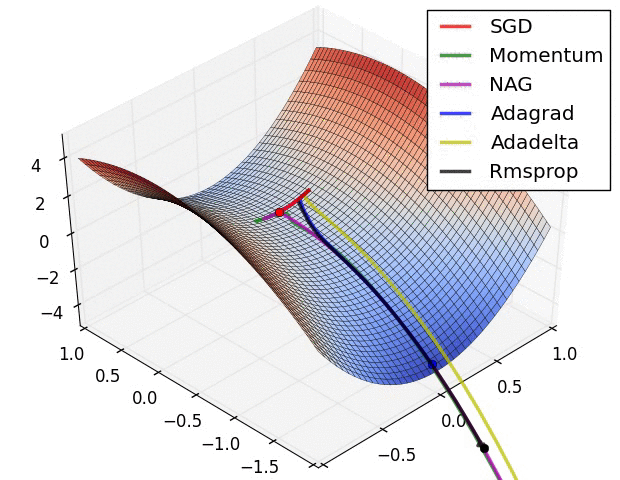
일반적인 SGD의 경우 미분값이 0이 되는 방향으로 나아가기 때문에, 위와 같이 global minimum은 아니지만 미분값은 0인 지점(saddle point)이 존재한다면 그 곳으로 수렴해버릴 수 있다. 이를 해결하기 위해 다양한 최적화 방법이 존재한다. 그림에서 보면 Adadelta, Adagrad 등 Adam 계열의 optimizer가 가장 효과가 좋으며 Momentum, RMSprop을 단독으로 사용한 경우도 결국 global optimum을 찾아감을 알 수 있다. 웬만하면 SGD를 단독으로 사용하기보다는 Adam optimizer를 사용하자.
Explanation & code for gradient descent optimization↓
Gradient Descent Optimization - Mini batch, Momentum, RMS, Adam, Learning rate decay
Mini-batch 전체 데이터셋을 batch size 단위로 자른다. 맨 마지막 batch는 적은 수의 데이터를 가짐. def batch_partition(X, Y, batch_size=64, seed=0): np.random.seed(seed) m = X.shape[1] # number of tra..
chloe-ki.tistory.com
Gradient Descent에서 batch 사용에 따른 차이

1) Whole-batch Gradient Descent
- 전체 데이터를 반복할 때마다 파라미터값을 업데이트한다. 1 update per epoch
2) Mini-batch Gradient Descent
- 전체 training sample을 m개씩 나눠 batch를 두고, 하나의 batch에 대한 gradient 계산이 완료될 때마다 파라미터를 업데이트한다. several update per epoch.
- 전체 샘플을 다 훑기 전에도 학습이 진행되기 때문에 학습이 빠르다.
3) Stochastic Gradient Descent
- training sample 한 개를 지나갈 때마다 파라미터를 업데이트한다. mini-batch GD에서 m=1인 특별한 케이스.
- 매 샘플 마다 학습이 이루어지기 때문에 가장 빨리 optima에 도달하지만, generality를 잃어 도달까지의 변동이 크고 optima 근처에 도달해도 수렴하지 않고 계속 주위를 왔다갔다 하게 된다.
- vectorization으로 인한 속도 향상 효과를 잃게 된다는 단점이 있다.
> 보통 샘플이 2000개 이하면 1번, 그 이상이면 m = 64,128,256,512 중 하나로 정한다. 또한 CPU/GPU 메모리 내에 들어가도록 주의해야 한다.
> 코드 상 차이점
< Whole-batch Gradient Descent >
for i in range(0, num_iterations):
forward_propagation(X)
cost += compute_cost(a, Y)
backward_propagation(a)
update_parameters(parameters, gradients)
< Mini-batch Gradient Descent >
for i in range(0, num_iterations):
for j in range(0, m):
forward_propagation(X[:,j])
cost += compute_cost(a, Y[:,j])
backward_propagation(a)
update_parameters(parameters, gradients)
Yoshua Bengio
- 먼저 직감적으로 이론을 생각해내지만, 처음에는 그게 왜 잘 되는지 모른다. 그냥 deep할수록 더 잘될거라는 직관이 있고, justification은 나중에 생김.
- 딥러닝과 뇌의 관계 : connectionists. 정보는 여러 뉴런에 걸처 분포된다. // jeffry hinton conference 2007
- 연구들 : long term dependency, curse of dimensionality, join distribution, autoencoder, stacks of rbm, attention mechanism
- 사람은 관찰과 탐험, 직관으로 세상을 이해한다. unsupervised learning. 정답을 주지 않고도 이런 것들을 컴퓨터가 학습하도록 만들어주어야함.
- 때때로는 간단한 질문을 하는 것이 중요한 다른 것들에 대해 생각해보게 만든다. 어떤 질문을 하는지가 중요하다. what makes training hard? rather than what algorithm is better?
- 프로그래밍을 많이 하기. 모듈을 import해서 실행만 하면 어떻게 돌아가는지 모른다.
- 1차 원칙에서 내가 직접 도출해보기.
- 읽고, 다른 사람의 코드를 보고, 나의 코드를 쓰고, 여러 번 실험을 해보고, 내가 하는 모든 것을 이해하기.
- 왜 이걸 하지? 를 질문하고 답을 찾아내기. 책을 읽든 스스로 찾아내든.
Andrej Karpathy
- 새로운 모델을 만드는 것보다 pre-trained fine tuning, transfer learning이 생각 이상으로 잘 돌아가지만 주목을 받지 못한다.
- 딥러닝은 성능향상과 general intelligence(NN이 어떻게 지능을 가지게 되는지)로 나누어지는 것 같다.
- 사람이 하는 일을 분해해서 기계가 할 수 있도록 만든 후 결합하려는 시도는 잘못되었다고 생각한다. 지금은 사람이 하는 일을 기능별로 나누어서 그에 필요한 것들(언어, 비전, 음성 등)을 구현하고 하나의 뇌로 합치고자 하지만, one complete dynamical system(AI)이 있고, 거기서 어떤 weight을 사용해야 원하는 지능적 행동을 얻어낼 건지 연구한다고 보고 있다.
LeNet-5

| Activation shape | Activation Size | # of Parameters | |
| Input | (32,32,3) | 3072 | 0 |
| Conv1 | (28,28,8) | 6272 | (5*5*3 + 1) * 8 = 608 |
| Pool1 | (14,14,8) | 1568 | 0 |
| Conv2 | (10,10,16) | 1600 | (5*5*8 + 1) * 16 = 3216 |
| Pool2 | (5,5,16) | 400 | 0 |
| FC3 | (120,1) | 120 | 400*120 + 120 = 48120 |
| FC4 | (84,1) | 84 | 120*84 + 84 = 10164 |
| Softmax | (10,1) | 10 | 84*10 + 10 = 850 |
FC layer의 bias는 뉴런마다 하나씩 있다. 층별로 하나 아님.
ResNet
- Conv Block이나 ID Block(Identity Block)에서, 이전의 output을 short cut (skip connection)을 이용해 한 번의 conv-norm-activation을 건너 뛰고 다음 activation 직전으로 전달


- iclr, icml, nips 논문
- probability, calculus, algebra, optimization
- boltzman machine, contrasting divergence
- reasoning
-
Machine Learning (기계 학습) - https://www.coursera.org/learn/machine-learning
-
AI for Everybody (모두를 위한 AI) - https://www.coursera.org/learn/ai-for-everyone
'VISION' 카테고리의 다른 글
| forward/back propagation 코드 구현 시 헷갈렸던 내용 정리 (0) | 2020.09.09 |
|---|---|
| Face recognition using model-encoded vector (0) | 2020.08.25 |
| PyTorch Basics (0) | 2020.08.02 |
| ResNet with Keras (0) | 2020.08.01 |
| Keras Basics (0) | 2020.07.27 |
