Siamese Network
두 입력데이터를 같은 네트워크에 통과시켜 다른 output을 얻어낸다. 마지막에 fully connected layer를 두어 output vector를 얻어내면 데이터베이스에 인코딩된 벡터를 저장하여 메모리 사용량을 줄일 수 있다. 얼굴 인식 태스크에서는 미리 얼굴 이미지들을 벡터로 인코딩해 저장해놓고, 테스트 환경에서 새로 인풋이 들어오면 같은 네트워크 모델을 이용해 벡터로 인코딩한 후 이를 데이터베이스와 비교한다.
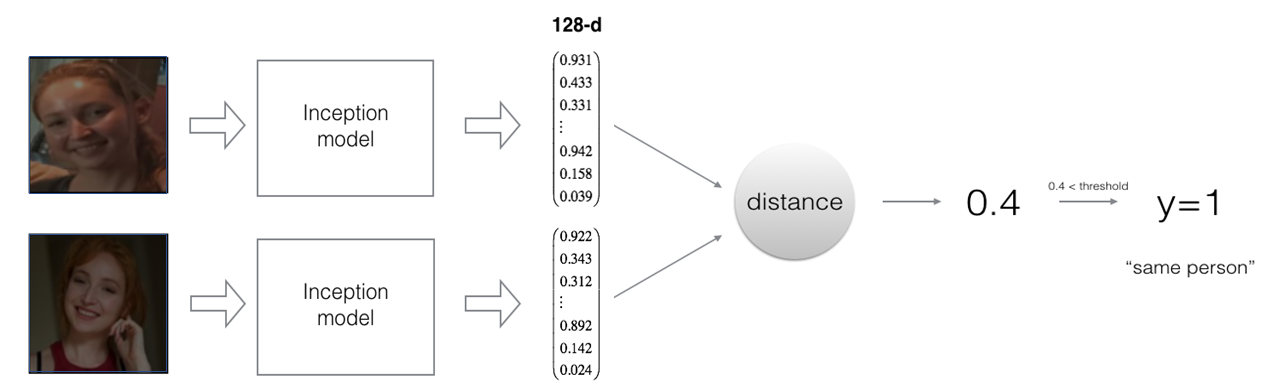
image = cv2.imread(image_path, 1)
image_encoded = model.predict(np.array([image]))
min = 100
for name, encoding in database.items(): # 데이터베이스 내 인코딩 데이터들과 비교
distance = np.linalg.norm(encoding - image_encoded)
if distance < min: # L2 distance가 가장 작은 데이터 찾아냄
min = distance
identity = name
if min > 0.7:
return False
else: #거리가 0.7보다 작은 경우만 True 리턴.
return True
Triplet Loss의 사용
얼굴인식의 경우 일치하는 얼굴을 감지하는 것 뿐 아니라 불일치하는 경우를 제대로 감지하는 것도 중요하다. 이를 위해 손실함수를 정의할 때 TRUE 데이터와의 차이는 줄이고 FALSE 데이터와의 차이는 최대화하는 방향으로 모델을 학습시켜 TRUE/FALSE 데이터를 감지하는 정확도를 동시에 높이도록 할 수 있다.
pdistance = tf.reduce_sum((anchor - positive)**2, axis=-1)
ndistance = tf.reduce_sum((anchor - negative)**2, axis=-1)
loss = pdistance - ndistance + alpha # alpha: 학습률을 높일 수 있도록 loss의 최소값을 지정
cost = tf.reduce_sum(tf.maximum(loss, 0.0))
* 회사에서 얼굴인식 시스템을 만드는 경우 직원 한 명에 대해 많은 얼굴 이미지를 얻을 수 없으므로 미리 학습된 네트워크를 사용한다.
* 학습 시 triplet loss function을 이용한다면 너무 쉬운 학습을 하지 않도록 어려운 positive, negative 쌍을 사람이 직접 선택해줄 수 있다.
'VISION' 카테고리의 다른 글
| Implementing convolution, padding, pooling, stride (0) | 2020.09.23 |
|---|---|
| forward/back propagation 코드 구현 시 헷갈렸던 내용 정리 (0) | 2020.09.09 |
| Coursera 딥러닝 과정 수강 - 배운 내용 정리 (0) | 2020.08.20 |
| PyTorch Basics (0) | 2020.08.02 |
| ResNet with Keras (0) | 2020.08.01 |
