YOLO(You Only Look Once) 알고리즘은 이미지에서 한 번의 CNN 연산으로 multiple object의 bounding box를 찾아낼 수 있다.
과제 : 자율주행 환경에서의 object detection task.
목표 : 주어진 주행 환경 이미지에서 object의 bounding box를 그리고 카테고리(클래스)를 알아내는 것.
이미지 전처리
from PIL import Image
image = Image.open(/path/)
resized = image.resize((608, 608), Image.BICUBIC)
image_data = np.array(resized, dtype='float32')
image_data /= 255.
그리드화
이미지를 인풋으로 받아 19*19의 그리드로 나눈다. 그리고 각 그리드에 대해 1)object가 존재할 확률(confidence), 2)존재한다면 그 bounding box 좌표(x,y,h,w)와 3)각 클래스에 속할 확률을 예측하는 DNN 모델을 학습시킨다.

그리고 나서 Deep CNN의 output이 담고 있는 confidence, xy, wh, class_probs을 각각 분리하여 텐서로 만든다.
confidence: (None, 19, 19, 5, 1)
xy: (None, 19, 19, 5, 2)
wh: (None, 19, 19, 5, 2)
class_probs: (None, 19, 19, 5, 80)
import keras.backend as K
# INPUT
# dnn_output : DNN의 마지막 레이어인 FC layer의 output. (m, 19, 19, 5, 85)
# anchor_box : anchor box array
# num_classes : 클래스 개수
output_dims = K.shape(dnn_output)[1:3] # 그리드의 높이, 너비 추출
height_index = K.arange(0, output_dims[0]) # 높이, 너비의 범위를 담은 1D 텐서 생성
height_index = K.tile(height_index, [output_dims[1]]) # tiled tensor(height x width)
width_index = K.arange(0, output_dims[1])
width_index = K.tile(K.expand_dims(width_index, 0), [output_dims[0], 1])
width_index = K.flatten(K.transpose(width_index))
conv_index = K.transpose(K.stack([height_index, width_index]))
conv_index = K.reshape(conv_index, [1, output_dims[0], output_dims[1], 1, 2])
conv_index = K.cast(conv_index, K.dtype(dnn_output))
dnn_output = K.reshape(dnn_output, [-1, output_dims[0], output_dims[1], num_anchors, num_classes + 5])
output_dims = K.cast(K.reshape(output_dims, [1, 1, 1, 1, 2]), K.dtype(dnn_output))
anchors_tensor = K.reshape(K.variable(anchor_box), [1, 1, 1, len(anchor_box), 2])
xy = K.sigmoid(dnn_output[..., :2])
xy = (xy + conv_index) / conv_dims
wh = K.exp(dnn_output[..., 2:4])
wh = wh * anchors_tensor / conv_dims
confidence = K.sigmoid(dnn_output[..., 4:5])
class_probs = K.softmax(dnn_output[..., 5:])
여기서 class_probs은 각 클래스에 속할 확률을 담고 있기 때문에, 속할 확률이 높은 클래스를 찾아내 지정해야 한다. 우선적으로 그리드가 오브젝트를 가질 확률(confidence)를 class_probs에 곱해서 score를 계산한 후 score가 너무 낮은 box들을 걸러낸다. 걸러낸 박스들의 점수, 좌표, 클래스를 각각 scores, boxes, classes에 저장한다.

grid_scores = confidence * class_probs # (19,19,5,80). 5는 anchor box 개수.
grid_classes = K.argmax(grid_scores, axis=-1) # score가 가장 높은 인덱스 추출, (19,19,5)
grid_class_scores = K.max(grid_scores, axis=-1) # score 추출, (19,19,5)
mask = grid_class_scores >= 0.5 # score가 0.5 이상인 index들만 True로. (19,19,5)
scores = tf.boolean_mask(grid_class_scores, mask)
boxes = tf.boolean_mask((xy, wh), mask)
classes = tf.boolean_mask(grid_classes, mask)
Non-max-suppression
하나의 오브젝트가 여러 번 감지되는 경우 가장 가능성이 높은 하나의 박스만 남겨주는 non-max suppression을 진행하는데, 먼저 가능성이 가장 높은 박스를 선택하고 그 박스와 iou(일치도)가 높은 박스를 제거해주면 된다. 텐서플로우에 구현된 tf.image.non_max_suppression을 이용할 수 있다.

max_boxes_tensor = K.variable(10, dtype='int32') # 남길 박스의 최대 개수 설정
K.get_session().run(tf.variables_initializer([max_boxes_tensor]))
index = tf.image.non_max_suppression(boxes, scores, max_boxes_tensor)
# 지정된 index만 남김
scores = K.gather(scores, index)
boxes = K.gather(boxes, index)
classes = K.gather(classes, index)
* IoU(Intersection over Union)
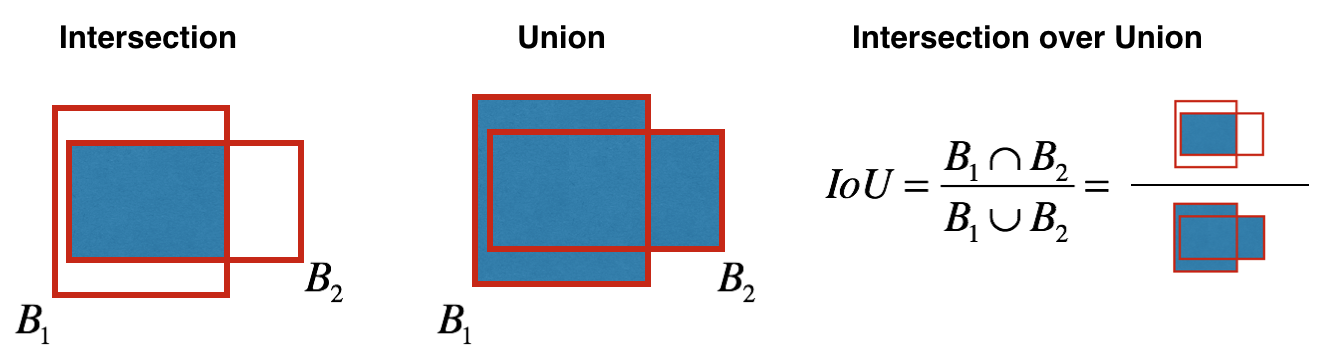
# INPUT
# BOX1 좌표: (box1_x1, box1_y1, box1_x2, box1_y2)
# BOX2 좌표: (box2_x1, box2_y1, box2_x2, box2_y2)
# INTERSECTION 좌표 찾기
x1 = max(box1_x1,box2_x1)
y1 = max(box1_y1,box2_y1)
x2 = min(box2_x2,box2_x2)
y2 = min(box1_y2,box2_y2)
intersection_width = xi2-xi1
intersection_height = yi2-yi1
intersection_area = max(inter_width*inter_height,0)
box1_area = (box1_x2-box1_x1)*(box1_y2-box1_y1)
box2_area = (box2_x2-box2_x1)*(box2_y2-box2_y1)
union_area = box1_area + box2_area - intersection_area
iou = intersection_area/union_area
결과 시각화
colors = generate_colors(class_names)
draw_boxes(image, scores, boxes, classes, class_names, colors)
image.save(os.path.join("out", image_file), quality=90) #box를 이미지 위에 저장
output_image = scipy.misc.imread(os.path.join("out", image_file))
imshow(output_image)
def draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors):
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle([left + i, top + i, right - i, bottom - i], outline=colors[c])
draw.rectangle([tuple(text_origin), tuple(text_origin + label_size)], fill=colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
'VISION' 카테고리의 다른 글
| 시각에 대한 생각들 (0) | 2020.11.28 |
|---|---|
| [강연] 컴퓨터 비전과 딥러닝의 현재와 미래 (0) | 2020.11.07 |
| [논문] Video object segmentation using space-time memory networks (0) | 2020.10.29 |
| Image style transfer (0) | 2020.10.05 |
| Sign language image recognition (TensorFlow) (0) | 2020.09.28 |

