Sign Language Dataset
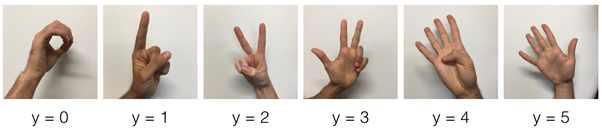
수화로 숫자를 표현한 1200개의 이미지 데이터셋이다. 10%인 120개를 test set으로 두고 나머지는 training set으로 활용한다. 인풋 이미지는 64*64 사이즈로 화질을 낮춰 계산량을 줄여주었다.
훈련용 인풋 데이터 로드 시 (1080, 64, 64, 3) 형태인데, reshape함수를 이용해 샘플을 구분하는 index 0만 남기고 나머지는 flatten 하여 (1080, 12288) 형태로 만든다. 그 후 이미지 하나를 하나의 column으로 만들기 위해 transpose하고, 정규화를 위해 데이터를 255로 나누어준다(zero mean).
X_train, Y_train, X_test, Y_test, classes = load_dataset()
X_train_flatten = X_train.reshape(X_train_orig.shape[0], -1).T # flatten
X_test_flatten = X_test.reshape(X_test_orig.shape[0], -1).T
X_train = X_train_flatten/255. # normalize
X_test = X_test_flatten/255.
Y_train = convert_to_one_hot(Y_train_orig, 6) # Convert labels into one-hot matrices
Y_test = convert_to_one_hot(Y_test_orig, 6)
linear - RELU - linear - RELU - linear - SOFTMAX의 3-layer 모델을 학습시키기 위해 각 layer의 파라미터 변수를 초기화하였다. initializer를 지정하기 위해 tf.get_variable()함수를 이용하며, W1, W2, W3는 xavier initializer로 매우 작은 값으로 초기화하고 b1, b2, b3는 0으로 초기화하였다.
def initialize_parameters():
W1 = tf.get_variable("W1", [25,12288], initializer = tf.contrib.layers.xavier_initializer)
b1 = tf.get_variable("b1", [25,1], initializer = tf.zeros_initializer())
W2 = tf.get_variable("W2", [12,25], initializer = tf.contrib.layers.xavier_initializer)
b2 = tf.get_variable("b2", [12,1], initializer = tf.zeros_initializer())
W3 = tf.get_variable("W3", [6,12], initializer = tf.contrib.layers.xavier_initializer)
b3 = tf.get_variable("b3", [6,1], initializer = tf.zeros_initializer())
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2, "W3": W3, "b3": b3}
return parameters
forward propagation 함수에서는 인풋 X와 현재까지의 파라미터를 받아 Z3까지의 연산을 수행한다.
def forward_propagation(X, parameters):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
Z1 = tf.matmul(W1,X)+b1
A1 = tf.nn.relu(Z1)
Z2 = tf.matmul(W2,A1)+b2
A2 = tf.nn.relu(Z2)
Z3 = tf.matmul(W3,A2)+b3
return Z3
현재까지 Z3는 (6,batch_size) 형태인데, cost 계산 시 tf.nn.softmax- 함수는 (batch_size, num_classes) 형태의 인풋을 받아 계산하기 때문에 transpose해주어야 하며 이때 logits는 scale되지 않은 값이어야 한다. 계산된 loss를 reduce_mean함수를 이용해 합산하여 cost에 저장하고 리턴해준다.
def compute_cost(Z3, Y):
logits = tf.transpose(Z3)
labels = tf.transpose(Y)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = labels))
return cost
현재까지 작성한 함수들을 이용해 모델을 학습시킨다. mini-batch를 반복할 때마다 X,Y가 새로운 값으로 바뀌기 때문에 placeholder를 사용한다. placeholder 선언 시 None을 활용하면 shape의 두번째 요소(column, 샘플 개수)가 ?로 설정되어 train, test set 간 샘플 개수가 달라도 같은 placeholder를 사용할 수 있게 된다.
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.0001,
num_epochs = 1500, batch_size = 32, print_cost = True):
m = X_train.shape[1]
costs = []
init = tf.global_variables_initializer()
X = tf.placeholder(dtype=tf.float32, shape=(X_train.shape[0], None))
Y = tf.placeholder(dtype=tf.float32, shape=(Y_train.shape[0], None))
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
with tf.Session() as session:
session.run(init)
for epoch in range(num_epochs):
epoch_cost = 0.
minibatches = randomize_batches(X_train, Y_train, batch_size)
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch
_ , batch_cost = session.run([optimizer, cost], feed_dict={X:minibatch_X, Y:minibatch_Y})
epoch_cost += batch_cost / batch_size
if print_cost == True and epoch % 100 == 0:
print ("Cost after epoch %i: %f" % (epoch, epoch_cost))
parameters = session.run(parameters)
correct_prediction = tf.equal(tf.argmax(Z3), tf.argmax(Y))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print ("Train Accuracy:", accuracy.eval({X: X_train, Y: Y_train}))
print ("Test Accuracy:", accuracy.eval({X: X_test, Y: Y_test}))
return parameters
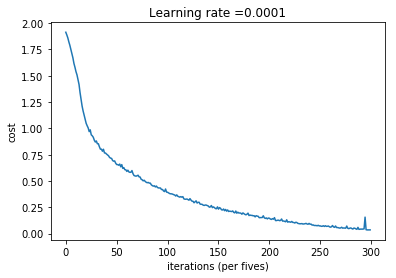
첫 시도에서는 learning rate=0.0001, batch_size=32, epoch=1500으로 시도하였고, 왼쪽 그래프처럼 균일하게 cost가 감소하였다. train accuracy는 99.9%였지만 test accuracy는 71.7%에 그쳤다.
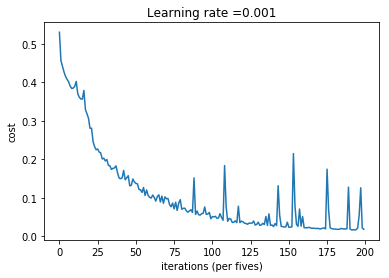
학습속도도 느리고 너무 overfit되는 것 같아 두 번째 시도에서는 learning rate=0.001, batch_size=64, epoch=1000으로 시도하였고, 반복 횟수가 적은데도 기존보다 더 낮은 cost를 얻을 수 있었다. train accuracy는 98.5%로 조금 낮아졌지만 test accuracy가 77.5%로 향상되었다.

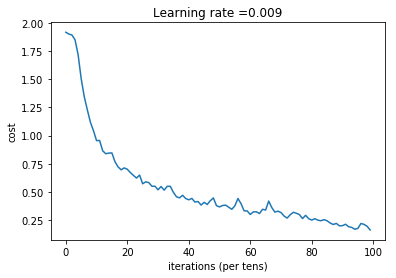
반면 batch size를 128로 늘렸을 때 cost는 0.18 정도로 낮은 수준에서 시작해 계속해서 내려가지만 train accuracy는 82.5%, test accuracy는 65%로 둘 다 크게 감소하였다. cost가 작은데 왜 accuracy는 떨어질까? batch size를 늘리면 더 많은 데이터를 단위로 파라미터를 업데이트한다. 그래서 초기 에러는 더 작게 나오지만 그만큼 파라미터를 더 잘 업데이트하는 효과는 떨어지는 것 같다. 에러를 줄이는 방향으로 업데이트가 이루어져야하는데 이미 에러가 작은 상태로 시작하기 때문이 아닐까 생각해보았다.
그래서 batch size를 다시 64로 줄이고 정규화를 위해 첫 레이어의 25개 노드 중 20%를 dropout하는 방법을 적용하였다. train accuracy는 높기 때문에 high variance라고 판단하였고, 이미지가 단순한 편이기 때문에 초기 레이어에서 복잡하게 학습할 필요가 없다고 생각해 dropout으로 모델 구조를 단순화시켰다. 그 결과 train accuracy 97.1%, test accuracy 78.3%로 test 정확도를 더 향상시킬 수 있었다. 현재는 1000개 정도의 데이터를 가지고 있지만 데이터의 양을 늘릴 수 있다면 더 정확도를 높일 수 있을 것이다.
Using Convolutional Neural Network
이번에는 convolution을 이용해 Conv-pool-conv-pool-FC 의 간단한 모델에서 학습시켜보았다.

Convolution을 이용한 경우 convolution을 통해 feature를 뽑아내 계산하기 때문에 epoch을 100회만 주어도 학습이 잘 되었다(왼쪽 그래프). train 94.1%, test 78.3%로 test set에서 비슷한 성능을 보여주었으나 cost에서 더 학습할 여지가 보여 learning rate을 0.01로 높여(오른쪽 그래프) 79.1%로 더 향상시킬 수 있었다. 그런데 train accuracy가 91%로 낮아져서, high bias라고 판단하였다. 그래서 모델을 더 deep하게 만드는 두 가지 시도를 해 보았다.
- 먼저 마지막 FC layer 이전에 뉴런 16개짜리 fully connected layer를 하나 더 추가한 경우 train accuracy는 94%, test accuracy가 83%로 둘 다 상승하였다.
- 두 번째 시도로 Convolution-pooling을 한 번 더 추가한 경우에는 loss minimization이 매우 효과적으로 이루어지는 것을 볼 수 있었고, train accuracy는 99%로 매우 높아졌으나 test accuracy가 74%로 떨어졌다. 필터 사이즈의 문제일 수도 있고, 데이터셋이 적은 상황에서 convolution layer만 늘려서는 모델이 training set에 지나치게 과적합하는 것으로 생각되었다.
'VISION' 카테고리의 다른 글
| [논문] Video object segmentation using space-time memory networks (0) | 2020.10.29 |
|---|---|
| Image style transfer (0) | 2020.10.05 |
| Implementing convolution, padding, pooling, stride (0) | 2020.09.23 |
| forward/back propagation 코드 구현 시 헷갈렸던 내용 정리 (0) | 2020.09.09 |
| Face recognition using model-encoded vector (0) | 2020.08.25 |

