Author : Seoung Wug Oh, Joon Young Lee, Ning Xu, Seon Joo Kim
1. 모델 기본 구조
비디오에서 움직이는 물체를 tracking 하는 모델을 만들 때 어떤 프레임의 정보를 참고하는 것이 가장 좋을까? 첫 번째 프레임에는 오브젝트의 정확한 경계선이 주어지기 때문에 reliable 하고, 직전 프레임은 가장 유사한 정보를 담고 있기 때문에 accurate 하다. 그래서 두 프레임을 모두 이용해 현재 프레임에서의 오브젝트를 찾는 것이 효과적이라고 알려져 있다. 이 연구에서는 더 나아가 첫 번째와 직전 프레임뿐 아니라 5 프레임 간격으로 수많은 프레임을 학습해 정확도를 높이는 방법을 개발하였다.
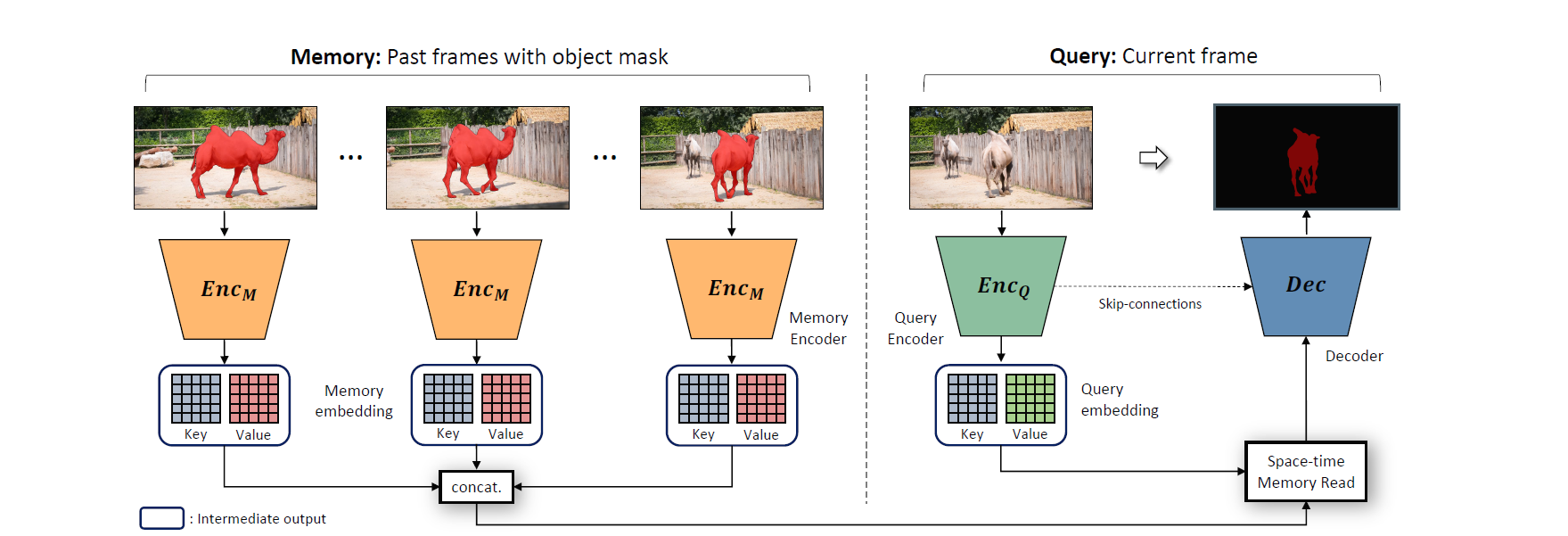
현재 프레임이 쿼리로서 메모리에 저장된 데이터를 바탕으로 오브젝트를 찾아내고, 이 프레임이 다시 학습 데이터로 메모리에 들어간다. 이렇게 더 많은 프레임이 저장되면 시, 공간적으로 참고할 수 있는 데이터가 많아지기 때문에 appearance, occlusion 변화에 더 잘 대응할 수 있다. 오브젝트를 찾아낼 때는 pixel-wise로 해당 픽셀이 foreground object에 해당하는지 background에 해당하는지 구분한다.
(출처 : 논문 내 이미지)
메모리 인코더는 이미지 프레임(RGB 채널)과 각각의 오브젝트 정보 입력으로 받고, 쿼리 인코더는 현재 프레임을 입력으로 받아 key와 value로 맵핑한다. 쿼리 프레임의 key와 value가 계산되면, 쿼리 key와 메모리 네트워크의 모든 프레임의 key의 유사도를 계산 후 메모리 네트워크의 weighted value를 얻어낸다. 이 value를 디코더가 입력받아 현재 프레임에서의 오브젝트(probability map)를 찾아낸다. 오브젝트 각각에 대해 모델을 학습시킨 후 merge 하는 방식으로 multi-object segmentation도 가능하다.
2. 모델 학습
먼저 이미지 프레임으로 pre-training이 이루어지고, fine-tune을 위한 main training은 Youtube VOS와 DAVIS 데이터셋의 비디오로 이루어진다. 중간 프레임들이 없어도(without temporal smoothness) 픽셀 간 매칭을 통해 학습하므로 영상처럼 프레임이 연결되는 데이터가 아닌 이미지컷 몇 장으로 사전학습이 가능하다(Perazzi). main training에서는 0 프레임부터 25 프레임까지 증가시키면서 건너뛰어가며 샘플링해 학습시킨다. 학습시킨 프레임은 5 프레임마다 메모리에 쌓이며, pre-training에는 4일, main training에는 3일이 걸렸다고 한다.
그런데 pre-training만 한 경우가 main training만 한 경우보다 퍼포먼스가 높다고 한다.
- 논문에는 3000개의 샘플 비디오는 여전히 부족하기 때문이라고 되어있는데.. 그보다 더 많은 데이터셋으로 검증을 해본 건 아니기 때문에 잘 모르겠다. 2000개일 때보다 3000개일 때가 더 퍼포먼스가 잘 나왔었을까? pre와 main은 학습 방법에 있어 이미지와 비디오라는 큰 차이가 있기 때문에 왜 이미지로 학습한 게 비디오로 학습한 것보다 더 좋을까 라는 의문이 더 든다. 논문에 자세히는 나오지 않았지만 pre-trainining을 위한 데이터셋을 만들 때 이미지에 affine transformation(회전, 확대, 변형 등)을 주어 변화에 강하도록 만들어주기 때문이 아닐까? 비디오 샘플을 통한 학습은 프레임을 건너뛴다고 해도 이미지 샘플을 crop 하거나 회전하는 것만큼 강하게 변형되진 않을 테니까. 추측/
- affine transformation을 통한 학습 효과가 좋을 것 같다. face recognition 프로그램을 만들 때 모든 샘플데이터는 얼굴을 중심으로 crop되어있었어야 했는데, 일반적으로는 배경이 차지하는 비중이 높다. 배경이 많든 적든 배경이 변화하고 오브젝트의 일부만 남더라도 동일한 오브젝트라는 것을 학습시키는 거니까 학습효과가 좋고, 비디오를 transform 시키는 것보다 훨씬 효율적인 것 같다.
처음 읽는 비전 논문인데 video에서의 space-time 개념에 대해 알게 되었고, 하나의 모델을 만들기 위해 들어가는 서브모델이나 튜닝 개념들을 볼 수 있었다.
- 인코더의 backbone 네트워크로 ResNet50이 사용되며, weight initialization을 위해 ImageNet이 이용된다.
- 학습 과정에서 랜덤하게 크롭된 패치가 사용되었다. cross-entropy loss, adam optimizer, learning rate = 0.00001
- 학습된 모델이 얼마나 일반화된 퍼포먼스를 보여주는지 확인하기 위해 cross-dataset validation을 한다. DAVIS로 학습시킨 후 VOS에서 테스트해보고, VOS에서 학습시킨 후 DAVIS에서 테스트해보는 식으로.
여기서는 모델을 구축하기 위해 과거의 많은 모델이나 개념이 사용되었고, 특히 NLP, VQA에서 쓰이던 memory모델이 활용되고 있었는데, 이렇게 다른 분야의 모델에서 아이디어를 얻어올 수도 있으므로 비전이 아닌 다른 분야의 방식도 잘 알고 있어야겠다는 생각이 들었다. 관련 강연에서도 이미지에서 쓰이던 CNN이 다른 분야에서도 높은 정확도를 보여 input을 이미지 형태로 변환해서 모델을 사용하는 식으로 많이 쓰인다고 들었다.
우리가 보는 비디오들은 컷 전환이 많은데, 그런 경우에는 컷이 시작될때마다 object를 새로 지정해주어야 하나? occlusion이 아니라 object가 아예 없는 장면이 1분 이상 지속되었다가 나타난다면 이 모델에서는 그 장면들은 어떻게 학습할까? 한 시간짜리 영상이 있을 때 중간중간 등장하는 오브젝트를 일일이 찾아낼 필요 없이 첫 프레임에서 지정하는 것 만으로 세그멘테이션 할 수 있으면 좋겠다. 프레임이 전환될 때 occlusion인지 장면 전환인지 알아내고, 장면이 전환되었을 때 메모리에 저장된 프레임들과의 유사성을 비교해서 유사할 경우 오브젝트를 찾아내고 유사하지 않을 경우 다음 장면이 전환될 때까지 학습을 하지 않는 방식으로 할 수 있을 것 같다.
tracking을 할 때 모든 프레임에서 경계선을 찾아내기보다는 step을 줘서 한 프레임 정도는 건너뛰면서 tracking해도 되지 않을까 하는 생각이 들었다. 모든 프레임을 쿼리로 보내기보다는 수 프레임씩 건너뛰면서 tracking 한 다음 뛰어넘은 만큼 그 평균치를 적용하는 방법으로. 이미 다 해봤겠지? 유의미한 runing time 단축 효과는 없으려나?? 쿼리로 보내지 않은 프레임은 학습에 들어가지 않기 때문에 조금 부정확하더라도 괜찮을 것 같고, 비디오는 초당 수십 개의 discrete 한 이미지를 연속적으로 보여주는 거라 각 이미지에서 오브젝트가 한두 픽셀씩 어긋나더라도 그 다음 프레임이 쿼리라면 다시 정확해지는 거고 그 정도의 차이는 사람의 눈으로 보기에 문제가 없지 않을까..
근데 왜 DAVIS에서의 자카드스코어를 보여줬을까? Youtube-VOS도 보여줬으면 좋았을 텐데.
그리고 그냥 떠오른 건데 대화할 때나 글을 쓸 때 사용하는 동사, 조사, 부사, 형용사의 빈도와 문장 내에서의 위치를 feature로 잡고 학습시켜서 text input을 주면 어떤 사람이 쓴 것인지 구분할 수도 있을 것 같다. 예를 들어 내 블로그의 전체 글을 학습 데이터로 놓고 분석하면 나중에 어떤 글이 내가 쓴 것인지 아닌지 구분(or 유사도 계산)할 수 있을 것이다.
더 알아보고 싶은 것들
- online & offline learning
- region similarity, contour accuracy
- video turing test
- 영상 자체에 대해서도 더 공부해보자.
'VISION' 카테고리의 다른 글
| [강연] 컴퓨터 비전과 딥러닝의 현재와 미래 (0) | 2020.11.07 |
|---|---|
| YOLO object detection for autonomous driving (0) | 2020.11.03 |
| Image style transfer (0) | 2020.10.05 |
| Sign language image recognition (TensorFlow) (0) | 2020.09.28 |
| Implementing convolution, padding, pooling, stride (0) | 2020.09.23 |


